Exciting times abound as we prepare to move our data processing and web serving infrastructure into Amazon’s EC2 Cloud. This move has become increasingly necessary with the substantial growth Wormly has seen in the past 18 months. Moving to the cloud allows us to offer a substantially more robust, higher availability system.
We will be performing the cut-over on Sunday October 17 at 11:30am (GMT+1100). We expect wormly.com will be unavailable for three hours during this period, which means you will not be able to modify monitoring configuration or view reports during this time.
Rest assured, though, that both uptime and server health monitoring will continue unaffected during this time. All data samples will be accrued and all alerts will be sent as normal.
We appreciate your patience during this time, and trust that the extra scalability and reliability that this move brings will be worth it.
If you have any queries at all, please don’t hesitate to contact our support desk.
Additional notes
The IP address used for health monitoring (inbounddata.wormly.com) will change from 66.228.123.50 to 184.72.226.23. This address will also become the source IP requesting the agent for Linux health monitoring installations.
The uptime monitoring node IPs will remain the same – an up to date list of monitoring node IPs can always be found here.
These can and will change over time, however, so we do not recommend creating IP-specific firewall rules for use with our service.
It’s been in private beta for quite a while now, so we’re very pleased to announce the immediate availability of the Wormly Developer API. Or ‘WAPI’ for everyone who loves an acronym.
Head over to:
http://www.wormly.com/developers
And check it out. Or just click the “Developer API” link that you will now find at the bottom of every page.
We’re still in the early stages of WAPI’s development, and consequently the API coverage of Wormly’s functionality is by no means complete. With your feedback and suggestions, though, we will be increasing API coverage as quickly as possible.
So drop us a line if we’re missing something crucial to you!
Primarily to assist those who on-charge the cost of notifications (SMS, phone calls, etc) to their customers, the alert log browser now includes the name and numeric ID of the host that triggered the alert.
These records can now be exported in .CSV format in addition to being viewed on screen.
The alert log browser can be found under Settings, Alert Recipients, View Alert History (toward the bottom of the page).
Due to (somewhat surprising) popular demand, we have implemented a system allowing customers to make pre-payments of any amount to their Wormly account.
The pre-payment is added to your account balance, and used to pay subsequent invoices automatically as they fall due.
Additionally, the process includes the creation of a print friendly invoice. This can be handy if your accounts department needs to see some paper before they hand over the cash, figuratively speaking.
The pre-payment invoice can then be settled via Visa, MasterCard or PayPal.
You can access the facility directly or via the Add funds link on the Billing page.
For a number of short periods between Feb 10 17:05 and Feb 11 09:36 (GMT+11) our New Jersey node (66.246.75.38) failed to deliver SMS and Phone call alerts for some customers.
This was caused by the node’s inability to resolve the DNS record needed to connect with both our primary and backup SMS gateways.
This in turn was caused by failures of the New Jersey data center’s DNS resolvers.
That, however, should not have been a problem because the standard operating environment (SOE) for all Wormly nodes includes a private DNS cache & resolver in order to prevent exactly this sort of problem.
However this particular data center provider uses a DHCP based network configuration process, which caused /etc/resolv.conf to be updated by their DHCP server, thus reverting DNS resolution back to their servers.
We have ensured that this cannot occur again by setting the immutable attribute on /etc/resolv.conf – something which is now part of our SOE.
Needless to say we apologize to the customers this has inconvenienced – and should mention that of course no charges were billed for the failed deliveries.
We’re also pleased to report that our internal monitoring alerted us to this situation, so even in the absence of contact from a couple of helpful customers we would have been able to identify and correct this problem in short order.
Thanks for your support and understanding!
Despite the prevalence of NTP, many sysadmins do not keep their servers running on the correct time. This is unfortunate, as it can make troubleshooting via log files much more difficult.
To celebrate 2008 finishing up one second longer than most years, Wormly now reports if a servers’ clock is running slow or fast via the Health Monitoring tab. e.g.:

So if you notice your servers running with an inaccurate clock, it might pay to put something like the following into cron:
/usr/bin/rdate -s time-nw.nist.gov
Note that this feature is currently only available for Linux servers. We hope to make it available for Windows servers in future.
Feature Deployed @ 2000-01-02 00:30 GMT
Owing either to high traffic events or server administrators going on holiday without a contingency plan, our users are likely to see lots of downtime throughout the festive season.
To help out, we’ve brought back the plain old telephone system.
As of today, phone call alerts are available in both our server health and uptime monitoring systems. For example, you can configure phone alerts if free disk space falls below 5% for more than 30 minutes – or if CPU load stays at 100% for a bit too long.
Calls are charged at a flat rate of $0.40 per call.
Naturally you can also configure a phone call if your site goes down altogether. A useful escalation schedule might be: Email when the downtime first occurs, send an SMS after 10 minutes, and make the phone call after 30 minutes.
We reckon that a phone call is still the best way to wake up your normally over-caffeinated sysadmin at 4am when The Bad Stuff happens. That little SMS *bleep* noise from their phone doesn’t always do the trick. And knowing that it’s all automatic is even better.
You can learn more about phone call alerts on this page.
Feature Deployed @ 2008-12-01 09:00 GMT
We’re very pleased to announce the immediate availability of our server health monitoring alert system; a feature which has been at the top of our most-requested list for some time now.
A simple screenshot explains it nicely:
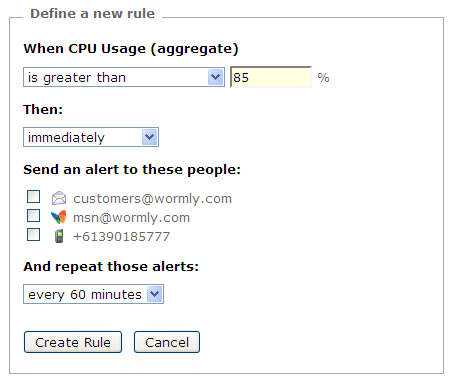
Naturally you can also read about the feature in more detail.
For existing users, simply click on your hosts’ Health Monitoring tab and follow the instructions to start using this new feature.
Feature Deployed @ 2008-11-14 09:00 GMT
It’s been of some concern here at Wormly HQ that loads of great new features are going unnoticed by you all – and our lack of a coherent announcement strategy was certainly to blame for this.
So starting today, you will be able to stay abreast of all new Wormly features and announcements by following the notification link shown within the Wormly console to this blog. Simple as that. Naturally you could add this feed to your reader as well.
And to celebrate we’ve just rolled out a new feature, keep reading the next post to learn about it!
I’m pleased to report we’ve rolled out another much-requested feature – the time-stamping of all alert messages.
Times are expressed in the timezone you’ve specified – the globally set zone or a host specific-one if available.
They’re shown in short form for the SMS & Short Email channels, e.g:
26/Aug 11:15
And long form for email and IM channels, e.g:
Tue, 26 Aug 2008 11:15:53 +1000
Feature Deployed @ 2008-08-26 02:00 GMT